The Accuracy Trap: Class Imbalance and Domain Knowledge in ECG Arrhythmia Classification
Numbers don’t lie, but they do mislead. Especially when we look at them without the full context. For example, say there’s a deep learning model that’s 91% accurate. While that number sounds impressive, the model is essentially useless. I recently built a baseline Convolutional Neural Network (CNN) model to classify Electrocardiogram (ECG) signals into five classes: Normal (N), Supraventricular (S), Ventricular (V), Fusion (F), and Paced (Q) (More detail about the classes and the dataset are provided below). This, in theory, is a textbook example of where deep learning (DL) models should shine 1. However, there’s one huge problem with the dataset: classes are severely imbalanced. One class makes up 83% of all the examples (the Normal class) and if the model simply predicts that everything in the dataset belongs to that class, then it would get an accuracy score of 83% yet fail to detect a single arrhythmia. This problem is called class imbalance and it can be notoriously hard to deal with for ML/DL projects.
1 Similar to image classification tasks where they’re quite good
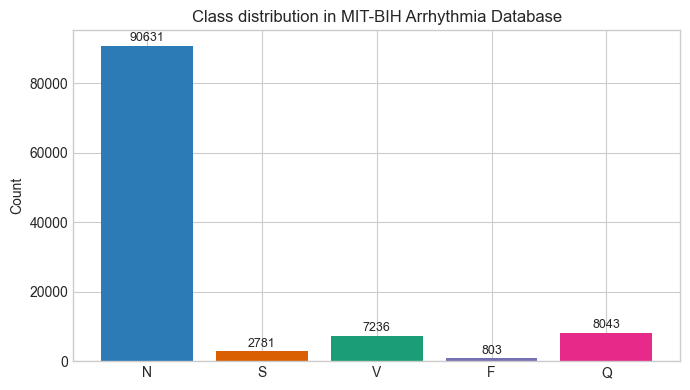
The Dataset
I used the MIT-BIH Arrhythmia Dataset (Moody and Mark 2001), which is one of the most widely used benchmarks in cardiac signal processing research. The dataset contains 48 half-hour recordings taken from 47 different patients using Holter monitors. Each recording contains two channels of ECG (Lead II and one of the V-leads), sampled at 360 Hz and two independent cardiologists manually reviewed and annotated over 109,000 individual heartbeats. I grouped the various annotations into 5 super classes, following AAMI guidelines (Association for the Advancement of Medical Instrumentation 1998 (Reaffirmed 2003)):
| Class | Clinical Description | Annotations Included |
|---|---|---|
| N (Normal) | Normal beat that follows the standard conduction pathways. Includes Bundle Branch Blocks: beats that look slightly wider due to a delay, but still follow the standard pathways | N, L, R, e, j |
| S (Supraventricular Ectopic) | Premature beat originating above the Ventricles (Atria or AV node). Travels down the normal pathways making it look morphologically similar to an ‘N’ beat, but arrives early | A, a, J, S |
| V (Ventricular Ectopic) | Abnormal beat originating in the ventricles, bypassing the normal pathways. Morphologically distinct from ‘N’ and ‘V’ beats (wide QRS complex) | V, E |
| F (Fusion) | A beat produced when a normal supraventricular impulse and a ventricular ectopic impulse activate the ventricles simultaneously. Resulting morphology is a fusion of ‘N’ and ‘S’ beats | F |
| Q (Paced/Unknown) | Beats that are artificially paced or too ambiguous/noise-corrupted to classify reliably | /, f, Q |
2 Beat class definitions follow (Association for the Advancement of Medical Instrumentation 1998 (Reaffirmed 2003)) and full annotation symbol list defined here. Supraventricular Ectopic (S) and Ventricular Ectopic (V) classes are abbreviated as Supraventricular (S) and Ventricular (V) in this article.
The morphological differences between classes are visible in the raw ECG signal but as we’ll see later, morphology alone isn’t always enough.
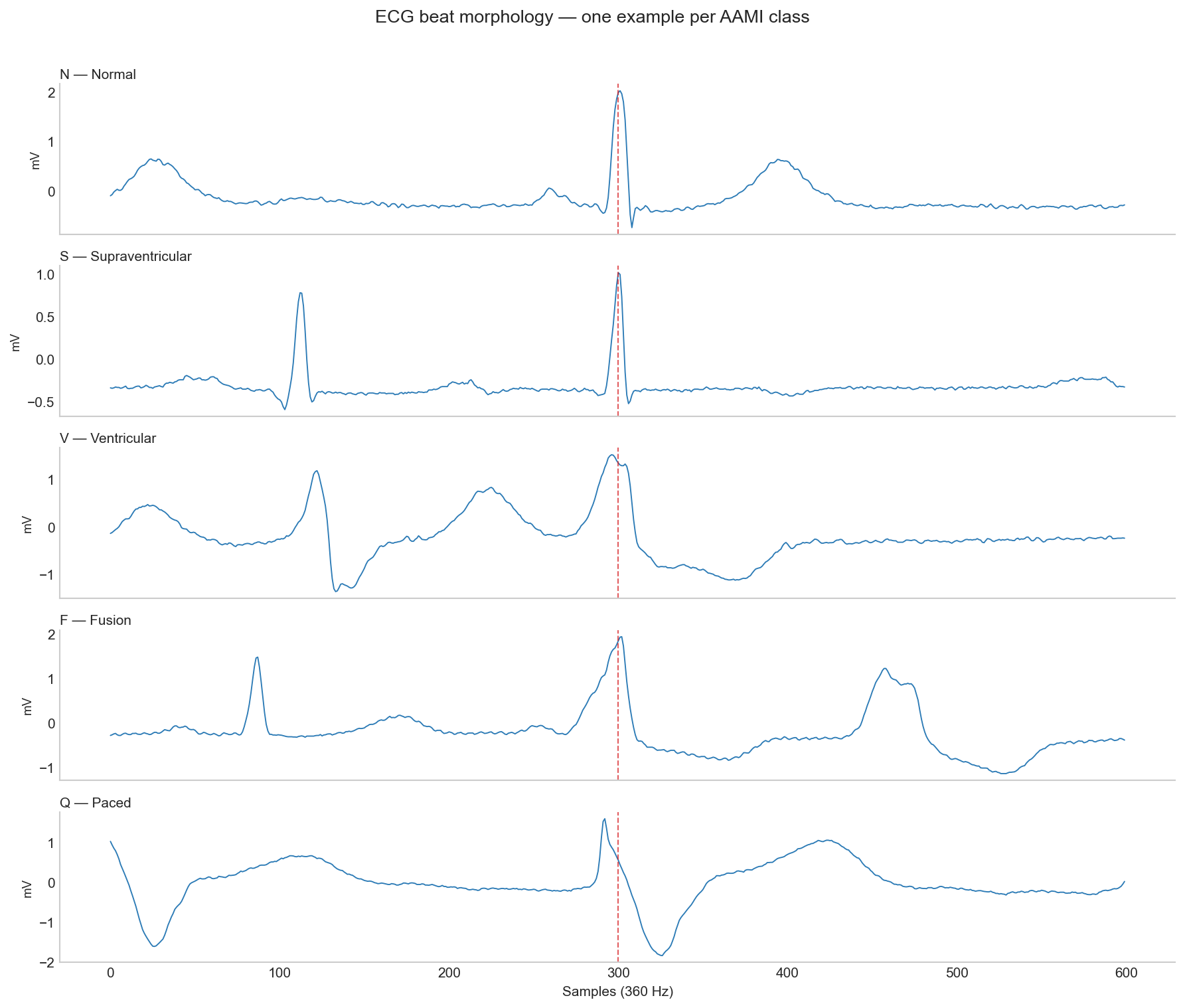
I used the standard DS1/DS2 patient-wise split defined by AAMI EC57 standard, which divides the data into 22 records for training and 22 for testing with no patient appearing in both. This ensures that there’s no data leakage from the Training set onto the Testing set. ECG morphology is highly individual and random beat-level splitting with same patients in both training and test set inflates every metric. In fact, most papers that report over 98% accuracy on this dataset use intra-patient splits.
Baseline CNN Model
To establish a baseline, I built an intentionally simple 1D CNN model with 3 convolutional layers, global average pooling and a five-class dense output layer. It takes in a 360 sample window centered around the R-peak of the beat. Here’s the normalized confusion matrix on the model’s predictions from the unseen DS2 test set:
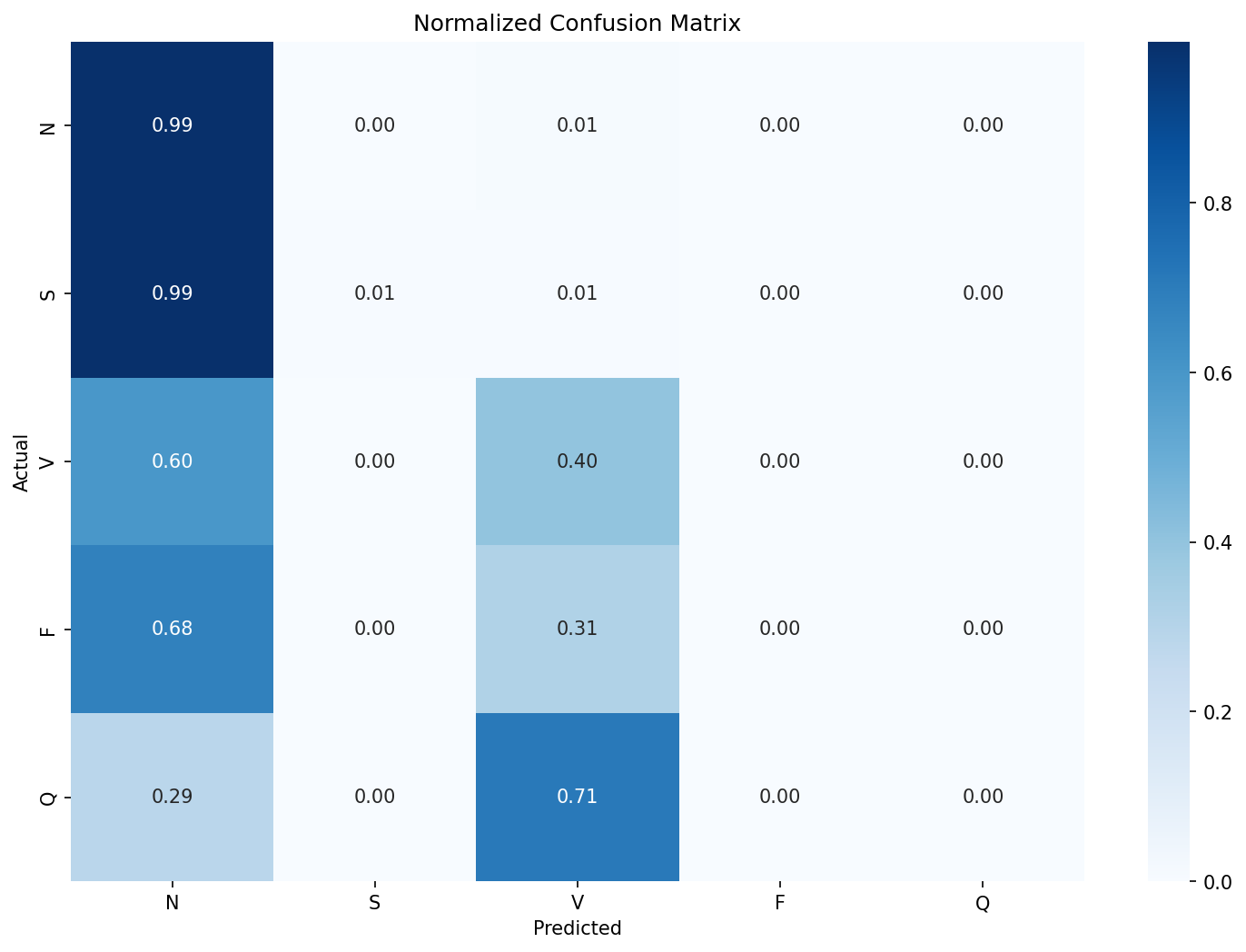
It’s clear that the model is just predicting most of the beats as N class and a few as V class. The recall for the rest of the classes is non-existent. The accuracy of this model would be 91% yet fail to detect a single arrhythmia class reliably and would be dangerous if deployed in a clinical setting. A better metric in this case would be the f1-score. The Macro-F1 for this model was 0.29.
| Class / Metric | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| N | 0.92 | 0.99 | 0.95 | 44235 |
| S | 0.22 | 0.01 | 0.01 | 1837 |
| V | 0.70 | 0.40 | 0.51 | 3220 |
| F | 0.00 | 0.00 | 0.00 | 388 |
| Q | 0.00 | 0.00 | 0.00 | 7 |
| accuracy | 0.91 | 49687 | ||
| macro avg | 0.37 | 0.28 | 0.29 | 49687 |
| weighted avg | 0.87 | 0.91 | 0.88 | 49687 |
Standard Fixes
The standard approaches in ML workflows when encountering this kind of class imbalance are to tweak the loss function or to generate ‘synthetic’ data for classes with fewer examples for the model to train on.
Weighted Cross-Entropy Loss
Instead of having all classes have the same weight 3, weighted cross-entropy loss assigns weight based on class distribution. This penalizes the network more for missing rare classes. The Ventricular (V) F1 score improved slightly (0.51 to 0.59), but the S class barely moved (0.01 to 0.07). The Macro F1 nudged along from 0.29 to 0.30.
3 As in Standard Cross-Entropy Loss, which was the loss function used in the baseline CNN model (and most simple classification models)
Focal Loss
Focal Loss (Lin et al. 2017) makes the network focus on ‘hard to classify’ beats by using a dynamically scaling loss that down-weights easy examples. This is the preferred loss function in standard ML workflows for datasets with severe class imbalance. However, in this case, it failed to outperform weighted cross-entropy loss 4.
4 A gamma value of 2.0 was used, which is the default. Read the original paper for more details
Synthetic Data (SMOTE)
SMOTE (Synthetic Minority Over-sampling Technique) is an ML algorithm that creates synthetic samples for under-represented classes by essentially interpolating the existing examples from that class 5. For this dataset and model, it provided best S class result so far (0.15) but failed to move the needle on other classes.
5 The math behind SMOTE and some its variants are presented here
To understand why SMOTE failed in this case, we only need to look at examples of the synthetic data. The Q class is at a severe disadvantage because there are only 8 real examples in the DS1 training split and interpolating between them to create 45,833 beats means the resulting synthetic beats are essentially just noise.
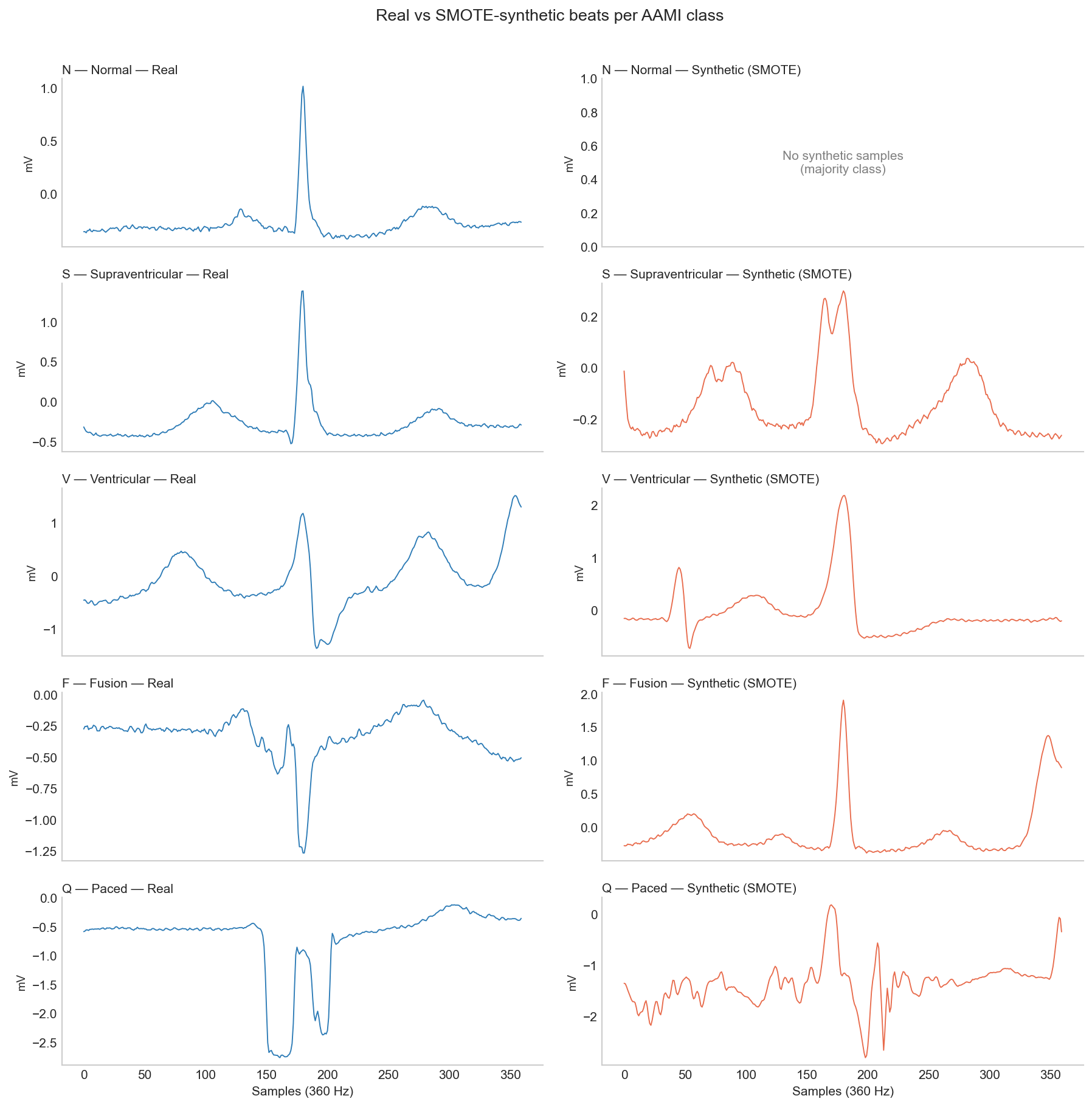
Ultimately, these are general purpose tools that lack domain knowledge. Applying them to a dataset with severe class imbalance is far less likely to succeed.
Domain Knowledge
Deep Learning models like the CNN are really good at extracting morphological features from a given signal - like edges, curves and slopes. This is why the baseline model does a decent job classifying V class, as their QRS complexes are distinctly wider than N beats. However, the model doesn’t know that what makes the S beats different from N beats is their timing. Cardiologists don’t just look at the shapes of individual beats but they also look at their timings (RR intervals) and S beats, although morphologically similar to N beats, are premature beats. A model that only looks at a beat’s morphology has no access to the timing of the beats before or after.
To fix this, I calculated 3 specific timing-related features for all the beats:
| Feature | Description |
|---|---|
| Pre-RR Interval | The time elapsed since the previous R-wave. |
| Post-RR Interval | The time until the next R-wave. |
| Local RR Ratio | The current RR interval divided by a moving average of the patient’s recent heart rate. |
The Pre-RR interval is clinically known as the ‘coupling interval’ and the Post-RR interval dictates the ‘compensatory pause’. These timing features play a big role when classifying the beats. For example, Ventricular beats typically have a full compensatory pause but a Supraventricular beat resets the sinus node so a full compensatory pause is not found, thereby appearing as a premature beat.
When calculating these features per class, the difference was obvious. Average pre-RR interval for N class was 0.778 seconds whereas for S class, it was 0.506 seconds. I updated the CNN architecture so these 3 features are added to the flattened morphological embeddings from the CNN, right before the final dense classification layer. The results were meaningful - especially for S and V classes. S class F1 score went up to 0.55 from 0.01 and V class F1-score also increased to 0.80.
Just adding these three numbers increased the overall macro-F1 score from 0.3 to 0.45 while the standard methods couldn’t improve it at all.
| Experiment | Accuracy | Macro F1 | S F1 | V F1 | F F1 |
|---|---|---|---|---|---|
| Baseline CNN | 0.91 | 0.29 | 0.01 | 0.51 | 0.00 |
| Weighted CE loss | 0.69 | 0.30 | 0.07 | 0.59 | 0.02 |
| Focal loss (\(\gamma=2\)) | 0.90 | 0.30 | 0.00 | 0.53 | 0.00 |
| SMOTE oversampling | 0.65 | 0.29 | 0.15 | 0.52 | 0.01 |
| CNN + RR features | 0.85 | 0.45 | 0.55 | 0.80 | 0.02 |
Grad-CAM
Numbers only tell part of the story. Like I wrote in the Activity Recognition post, it’s important to figure out what features a deep learning model is actually learning or where it’s falling short. To do this, I implemented a widely used technique called Grad-CAM (Gradient-weighted Class Activation Mapping) (Selvaraju et al. 2020). Put simply, Grad-CAM visually highlights the regions in the signal (or image) that had the most influence in the network’s classification decision. I hooked it up to the final convolutional layer and ran some examples through it to produce the heatmaps below.
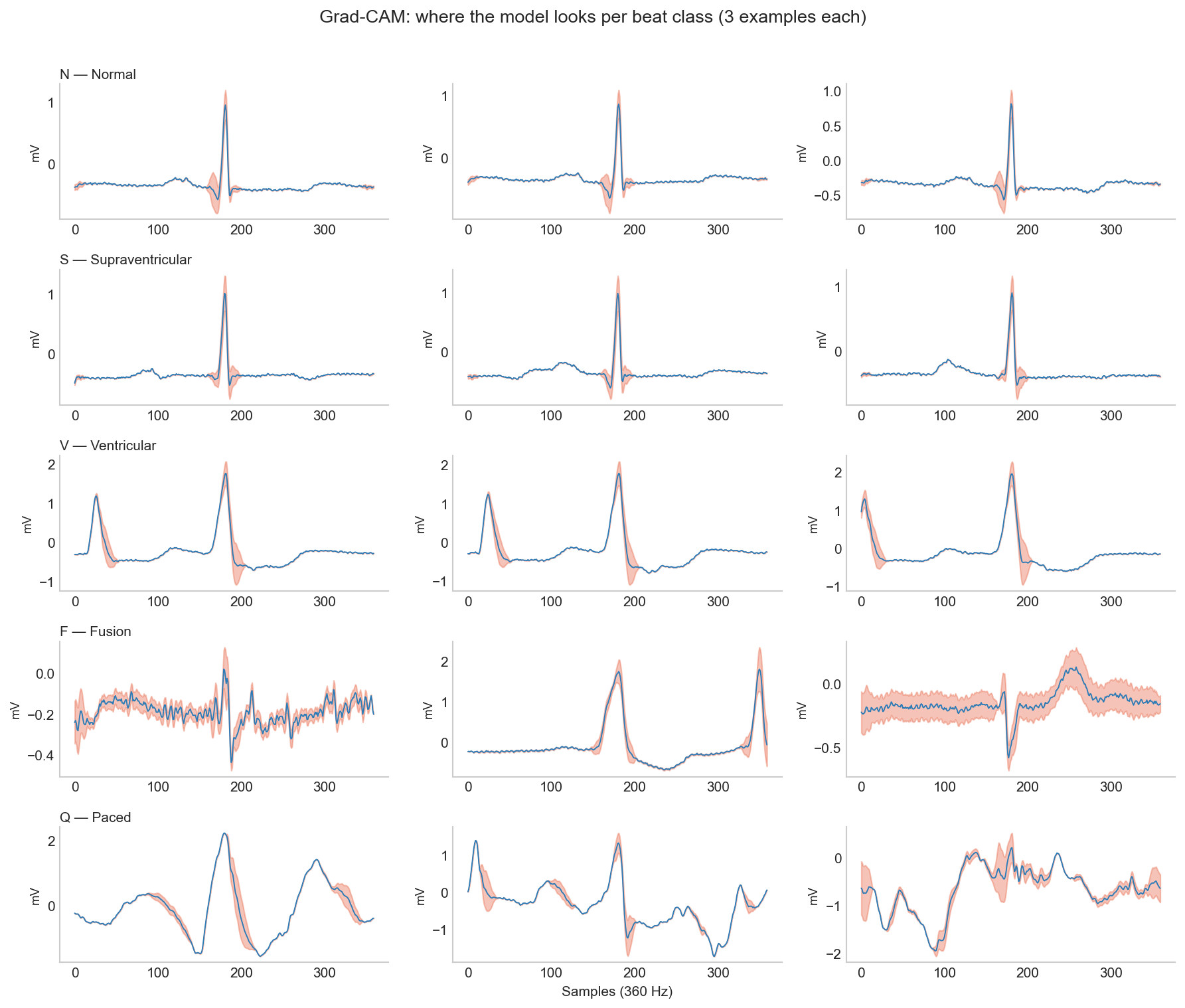
| Beat Type | Attention Analysis |
|---|---|
| N & V Beats | Consistent focus on meaningful signal parts (e.g., wide QRS). The model learned something real. |
| S Beats | Consistently focuses on QRS to verify shape. Injected RR features do the heavy lifting for classification. |
| F Beats | Completely inconsistent attention. No learned strategy, explaining the dismal F1 score. |
| Q Beats | Diffuse, wildly different heatmaps. The model is just guessing. |
Reading across the rows of the figure gives us valuable information about the model’s performance and tells us whether the model learned something clinically grounded. For F and Q classes, the problem is in the dataset. It is extremely difficult to build any model to accurately detect a morphologically ambiguous class with only 414 training examples.
Conclusion
I kept things intentionally simple in this project - a simple CNN model, standard mitigation strategies and just three timing features added - because my main aim was to explain the need for clinical grounding. There are some papers that have achieved a high F1-score on this dataset 6 by using advanced methods such as a CNN+BiLSTM architecture (Hassan et al. (2022)) that takes in longer windows (3 to 5 beats) as input so it can calculate some of the timing features that I hand-engineered. Another technique is to use a Transformer architecture with multi-headed attention mechanism (Hu, Chen, and Zhou (2022)) where instead of treating every part of the signal equally, the model learns to dynamically focus its attention on specific temporal areas of the signal.
6 Once again, be sure to check the train-test split when reading any paper that uses this dataset. A lot of them don’t use the strict DS1/DS2 patient-level split that I used here
Beyond architecture, there’s also personalization. I chose a very strict train-test split on purpose to make sure that there wasn’t any patient data leakage from training data to the test data. This ensures that the results are accurately representative of what the model might do if it encounters a completely new patient. For practical purposes, however, it is possible that the real-time system can use a short amount of patient specific data (say, the first 2-5 minutes) to perform patient-specific calibration that can meaningfully improve accuracy and recall.
My main takeaway from this project is that clinical grounding is essential at every step of the AI development process. From how to split the dataset, what features to extract, what evaluation metric to use and what explainability techniques to choose: all of them should align with existing clinical knowledge and fit the clinical use case. The biggest improvement in this project didn’t come from a better algorithm, but from asking what a cardiologist would look at.
References
Citation
@misc{ravi2026,
author = {Ravi, Mani},
title = {The {Accuracy} {Trap:} {Class} {Imbalance} and {Domain}
{Knowledge} in {ECG} {Arrhythmia} {Classification}},
date = {2026-04-22},
url = {https://maniravi.com/projects/ecg-arrhythmia-mit/},
langid = {en}
}